Custom Web Scraping for Industrial Price & Product Catalogs: A Complete Guide

Industrial businesses need accurate pricing and product data from competitors, suppliers, and distributors to make informed decisions. The problem? Generic web scraping tools break when faced with industrial catalog complexity. Custom web scraping solves this by building extraction logic tailored specifically to your target websites and data requirements. This guide explains what custom web scraping actually is, when you need it instead of standard tools, and how it works for industrial price and product catalogs.
What Is Custom Web Scraping and How Does It Differ from Standard Tools
Understanding Custom Web Scraping
Custom web scraping means purpose-built data extraction designed specifically for your target websites rather than trying to force a generic tool to work. Think of it like custom software development versus buying something off the shelf—you get exactly what you need, built to handle the specific challenges your data sources present. This matters because industrial catalogs don't behave like consumer ecommerce sites that standard scrapers are designed for.
Standard Tools vs. Custom Solutions
Standard price scraping tools work fine for straightforward websites with common structures. An ecommerce web scraper built for retail sites assumes simple product pages with basic pricing. But industrial catalogs? They use authenticated distributor portals that require login. They load pricing dynamically through JavaScript. They embed specifications in tables that vary by product category. Generic tools either fail completely or require so much manual configuration that you're essentially building a custom solution anyway—just with worse results.
Why Industrial Price & Product Catalogs Need Custom Web Scraping
The Complexity of Industrial Catalogs
Catalog data extraction for industrial markets deals with complexity that doesn't exist in consumer retail. Technical specifications come in precise formats that matter—thread pitch, material grade, temperature ratings. Pricing isn't a single number; it's tiered based on volume with different rates for 10 units versus 100 versus 1,000. Products carry certifications and compliance documentation. Cross-reference tables link parts to applications and compatible equipment. This data exists across inconsistent formats on different supplier sites, and extracting it accurately requires custom logic for each source.
Data Scattered Across Multiple Sources
The data you need isn't conveniently located in one place. Competitor pricing appears on various distributor websites, each with different layouts. Manufacturer catalogs use completely different structures from each other. Supplier portals require authentication and session management. Industry-specific databases and directories each have proprietary formats. Some suppliers still publish PDF catalogs that need structured extraction. Custom web scraping handles this fragmentation by building specific extraction logic for each source while following robots.txt protocol to ensure responsible data collection.
Dynamic Content Challenges
Modern industrial catalogs increasingly use JavaScript frameworks that render content dynamically. Product pages load through AJAX calls. Catalogs implement infinite scroll instead of pagination. Interactive configurators let users customize products before showing pricing. These patterns break traditional scrapers that expect static HTML. Custom solutions handle JavaScript rendering, manage AJAX requests, and navigate interactive elements—capabilities essential for industrial automation of data collection from modern websites.
Common Use Cases for Custom Web Scraping in Industrial Markets
Competitive Price Intelligence
Tracking competitor pricing across hundreds of product categories requires custom price scraping tools that understand your specific market. You need to capture not just list prices but volume-based tiers, regional variations across distributor locations, and promotional pricing that appears temporarily. Custom solutions map identical products across different competitor numbering systems and track price changes on schedules that match how frequently your market moves—hourly for volatile categories, daily for most products, weekly for stable items.
Product Catalog Aggregation
Building comprehensive product databases from multiple supplier catalogs means extracting technical specifications in formats that vary by manufacturer. Catalog data extraction pulls specifications, product images, technical drawings, compatibility information, and certification documents. This creates searchable databases where you can compare products across suppliers, identify alternatives, and track when suppliers add or update products. The aggregated intelligence beats manually browsing individual catalogs by orders of magnitude.
Supplier and Distributor Monitoring
Data extraction services track which products each distributor actually carries, revealing market coverage and competitive positioning. Stock availability monitoring across locations identifies supply constraints before they impact your operations. Lead time extraction shows delivery timelines changing over time. Compiling supplier certifications and compliance documentation in one database beats manually requesting this information from each supplier repeatedly.
Key Components of Effective Custom Web Scraping Solutions
Technical requirements that separate working solutions from failed projects:
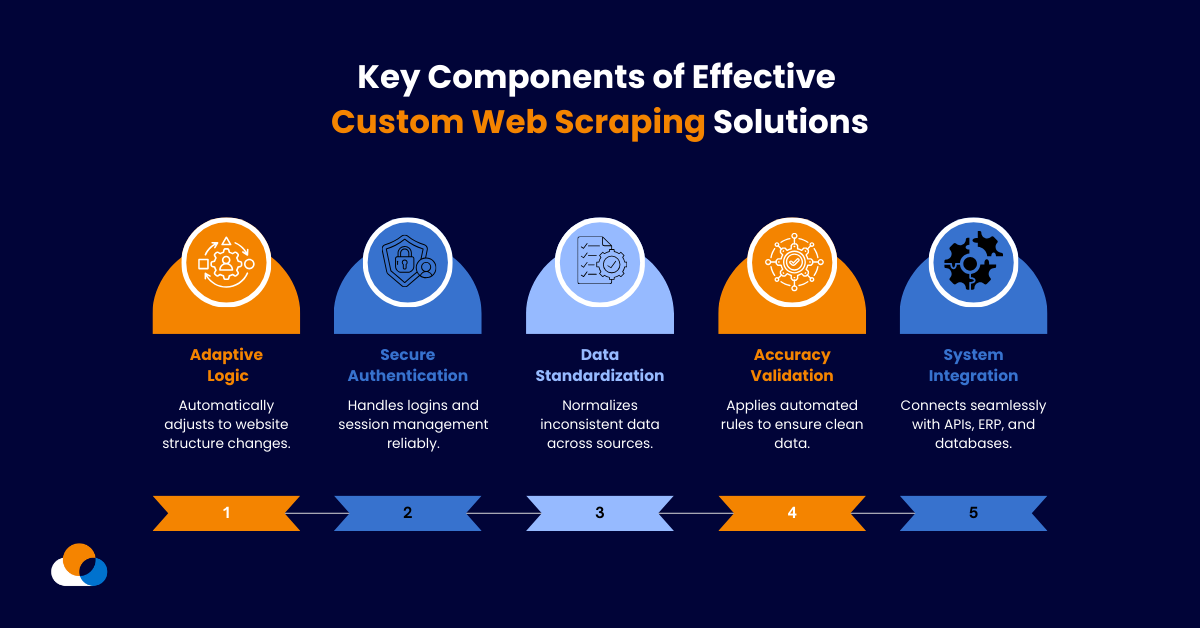
- Adaptive extraction logic that handles website structure changes without breaking
- Authentication management for distributor portals requiring login credentials
- Data normalization to standardize formats across inconsistent sources
- Validation rules ensuring extracted data meets accuracy requirements
- Integration capabilities delivering data to your systems via API or database connections
Bespoke scraping solutions get built with these components configured specifically for your requirements rather than generic implementations that half-work.
When to Choose Custom Web Scraping Over Standard Tools
Indicators you need custom solutions:
- Standard ecommerce web scraper tools fail on your target industrial sites
- Websites require authentication or complex multi-step navigation
- Data structures vary significantly across your sources
- Accuracy requirements exceed what generic tools deliver
- Integration with existing business systems is non-negotiable
The cost-benefit calculation is straightforward. Custom web scraping has higher upfront development costs but dramatically lower ongoing maintenance expenses. Generic tools seem cheaper initially but require constant fixes when sites change, deliver incomplete or inaccurate data, and often need manual supplementation. If the data matters to your business decisions, custom solutions justify their cost through reliability and accuracy.
How Custom Web Scraping Works: The Development Process
Implementation starts with discovery, identifying target websites, mapping data requirements, and understanding update frequency needs. Development builds extraction logic specific to each source, handles edge cases like missing data or format variations, and validates accuracy against sample datasets. Deployment sets up automated extraction schedules, implements monitoring for source website changes, and establishes alert systems for failures. Ongoing maintenance addresses site updates and adds new sources as requirements evolve.
Best Practices for Industrial Catalog Scraping
Responsible custom web scraping respects technical and legal boundaries. Technically, this means respecting robots.txt files, implementing appropriate rate limiting so you don't impact website performance, using proper user agents, and caching results to minimize redundant requests. Legally and ethically, it means collecting only publicly available data, complying with website terms of service where reasonable, following data protection regulations, and maintaining transparency about data collection practices. Professional data extraction services build these considerations into their solutions from the start.
Data management practices matter too. Regular validation confirms extracted data remains accurate as source sites evolve. Version control for extraction logic enables rollback when updates cause issues. Audit trails document data provenance for compliance purposes. Backup and archival strategies prevent data loss.
Custom web scraping solves data collection challenges that generic tools simply can't handle, particularly for complex industrial price and product catalogs. When standard scrapers fail on authenticated portals, dynamic content, and inconsistent data structures, custom solutions provide the extraction logic specifically designed for your requirements. For businesses serious about data-driven decision-making in industrial markets, custom web scraping transforms data collection from a persistent headache into automated infrastructure.
Ready to Automate Your Industrial Catalog Data Collection?
WebDataGuru specializes in building custom web scraping solutions for complex industrial applications where off-the-shelf tools fall short. Our team has over a decade of experience handling authenticated distributor portals, dynamic pricing structures, and technical specification extraction that industrial markets require.
Whether you need competitive price monitoring, comprehensive catalog aggregation, or supplier intelligence, we build bespoke scraping solutions tailored to your specific data sources and business requirements. Schedule a consultation to discuss your industrial catalog scraping needs and discover how custom data extraction services can transform your competitive intelligence.
FAQ: -
Custom web scraping is built specifically for your target sites and data needs, while standard tools are generic. Industrial catalogs with authentication, dynamic content, and tiered pricing require tailored extraction for accuracy.
2. How much does custom web scraping cost compared to off-the-shelf tools?
Custom solutions have higher upfront costs but lower long-term maintenance and better reliability. Generic tools often break, miss data, or can’t access authenticated sources—raising total ownership costs.
3. How long does it take to deploy a custom scraping solution?
Simple projects can launch within 1–2 weeks. Multi-source, authenticated, and ERP-integrated solutions typically take 4–6 weeks from scoping to deployment.
4. Can custom web scraping handle login-protected websites?
Yes. Custom solutions manage login automation, session handling, and authentication—essential for accessing distributor portals and supplier databases.
5. Is custom web scraping legal for competitor pricing data?
Yes, when collecting publicly available information responsibly, following regulations, and respecting website policies and compliance standards.
